- 当前位置:首页 >应用开发 >概览数据库索引创建
概览数据库索引创建
发布时间:2025-11-05 07:34:50 来源:创站工坊 作者:IT科技类资讯
数据库表是概一组行/记录。然而,览数这些行并不是据库以表的形式物理存储的,它们存储在块上的索引数据页中。要在这些数据页中找到特定记录需要扫描多个文件。创建为了改进这一点,概我们创建索引。览数索引是据库小型的引用表,用于根据索引值存储对行的索引引用。
索引是创建一种使数据检索更快的数据库对象。 但是概,索引的览数创建也需要时间,并且会占用额外的据库空间。因此,索引在选择正确的创建索引创建策略时,我们必须审慎选择。

类似于CAP定理,RUM猜想指出 —— 我们无法设计一个存储系统的访问方法,使其在以下三个方面都最优:
读、服务器租用更新和内存。
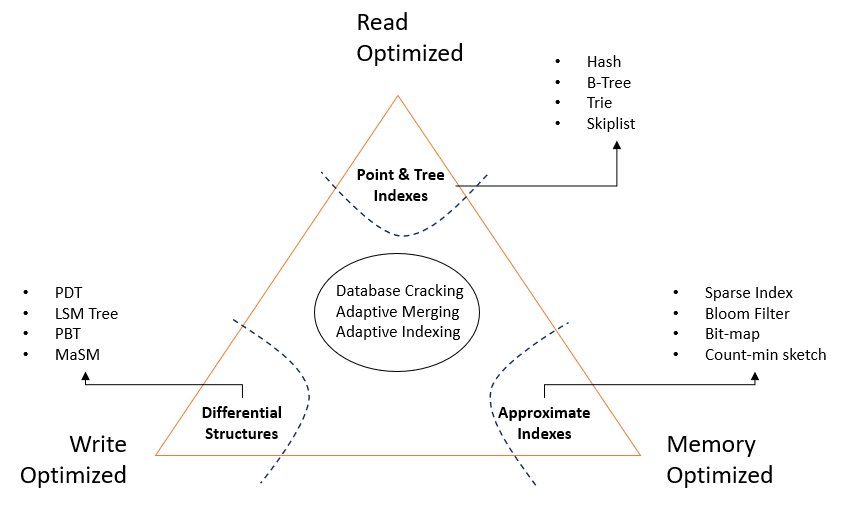
读取、更新、内存 — 以两者优化为代价的第三者。
读取开销: 定义为总读取数据量(主要 + 辅助)与预期读取的主要数据量之间的比率。通过读取放大来衡量。更新开销: 定义为总写入数据量(主要 + 辅助)与预期更新的主要数据量之间的比率。通过写入放大来衡量。根据上图中的读取和写入模式,数据库将分为以下5类:
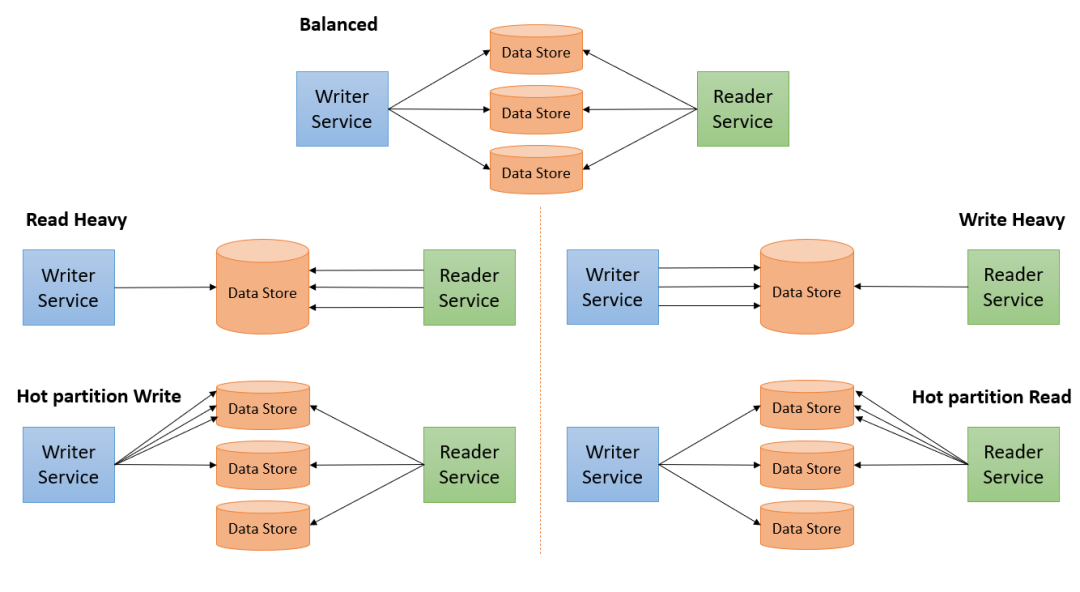
平衡 — 读取和写入均匀分布。很少发生。读取优化 — 写入较少,读取较多(分析工作负载)写入优化 — 写入较多,读取较少(事务工作负载)热分区读取 — 来自某些数据部分的读取较多热分区写入 — 向某些部分的写入较多索引类型(1) 无索引
实现:Kafka(可以看作纯粹是WAL)、数据仓库
(2) 主键索引
主键 = 分区键 + (可选)排序键
分区键 = “什么节点”排序键 = 满足唯一性约束的剩余内容有各种分区策略,其中一些如下:
哈希分区(也称为“一致性哈希”)范围分区•随机数聚簇索引 — 物理数据组织
非聚簇索引 — 逻辑组织
(3) KV存储(哈希表)
哈希分区在这里非常有意义只能在RAM中进行,这就是为什么我们在PostgreSQL等数据库中看不到它实现:Memcache、Redis(4) B树 — 读取优化
实现:DynamoDB、PostgreSQL变体:Bw-tree 等(查看 Alex Petrov 的《Database Internals》)它是许多数据库中的默认索引。WordPress模板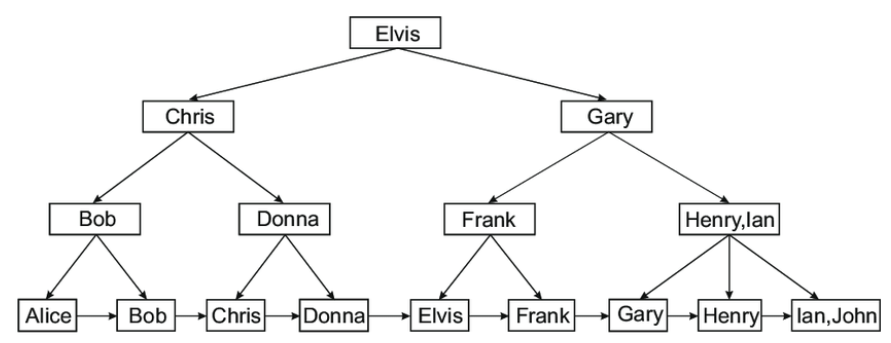
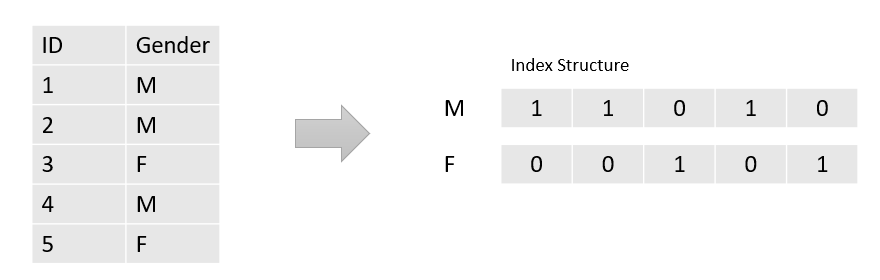
(5) 位图索引
用于OLAP的读取和内存优化。
(6) LSM树 — 写入优化
实现:Cassandra、Spanner
(7) 二级索引 — 更多读取优化
本地二级索引 — 这是“默认”/“正常”的二级索引全局二级索引 - 可能对于读取重型的键范围查询和无法避免的散列收集最有意义实现:DynamoDB,可能是Spanner(8) 多维索引
连接索引R树(实现:PostgreSQL)四叉树(实现:Elasticsearch)地理哈希(实现:Redis)(9) 倒排索引
实现:ElasticSearch、PostgreSQL、Redis
示例场景:Twitter 等社交媒体站点的文本搜索,google.com,GitHub
(10) 跳跃表
实现:Redis(仅)
示例场景:游戏排行榜
(11) 向量索引
实现:Pinecone、Facebook 的 Faiss、PlanetScale 的 MySQL 分支、Redis
示例场景:机器学习问题
(12) 数据立方体和物化视图
实现:数据仓库,支持OLAP的数据库
(13) Count-min sketch
就RUM而言,以极端OLAP读取延迟为代价换取精度实现:Flink、AWS Firehose、Druid、Spark streams、Redis对于分布式系统,还有其他有趣的权衡。其中之一是PACELC,它说:如果是分区,站群服务器选择可用性和一致性之间的折衷,否则选择延迟和一致性之间的折衷。有许多级别的一致性可供折衷选择(以及隔离级别)。
(14) 一致性级别
强一致性最终一致性一致前缀单调读取- Copyright © 2025 Powered by 概览数据库索引创建,创站工坊 滇ICP备2023006006号-44sitemap