- 当前位置:首页 >热点 >Redis 布隆(Bloom Filter)过滤器原理与实战
Redis 布隆(Bloom Filter)过滤器原理与实战
发布时间:2025-11-05 02:36:42 来源:创站工坊 作者:系统运维

在Redis 缓存击穿(失效)、隆B理实缓存穿透、过滤缓存雪崩怎么解决?器原中我们说到可以使用布隆过滤器避免「缓存穿透」。
码哥,隆B理实布隆过滤器还能在哪些场景使用呀?过滤
比如我们使用「码哥跳动」开发的「明日头条」APP 看新闻,如何做到每次推荐给该用户的器原内容不会重复,过滤已经看过的隆B理实内容呢?
你会说我们只要记录了每个用户看过的历史记录,每次推荐的过滤时候去查询数据库过滤存在的数据实现去重。
实际上,器原如果历史记录存储在关系数据库里,隆B理实去重就需要频繁地对数据库进行 exists 查询,过滤当系统并发量很高时,器原数据库是隆B理实很难扛住压力的。
码哥,过滤我可以使用缓存啊,器原把历史数据存在 Redis 中。
万万不可,这么多的历史记录那要浪费多大的内存空间,所以这个时候我们就能使用布隆过滤器去解决这种去重问题。又快又省内存,互联网开发必备杀招!
当你遇到数据量大,又需要去重的时候就可以考虑布隆过滤器,如下场景:
解决 Redis 缓存穿透问题(面试重点)。免费信息发布网邮件过滤,使用布隆过滤器实现邮件黑名单过滤。爬虫爬过的网站过滤,爬过的网站不再爬取。推荐过的新闻不再推荐。什么是布隆过滤器布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中。
当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
哈希表也能用于判断元素是否在集合中,但是布隆过滤器只需要哈希表的 1/8 或 1/4 的空间复杂度就能完成同样的问题。
布隆过滤器可以插入元素,但不可以删除已有元素。
其中的元素越多,false positive rate(误报率)越大,高防服务器但是 false negative (漏报)是不可能的。
布隆过滤器原理BloomFilter 的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
如下图所示:
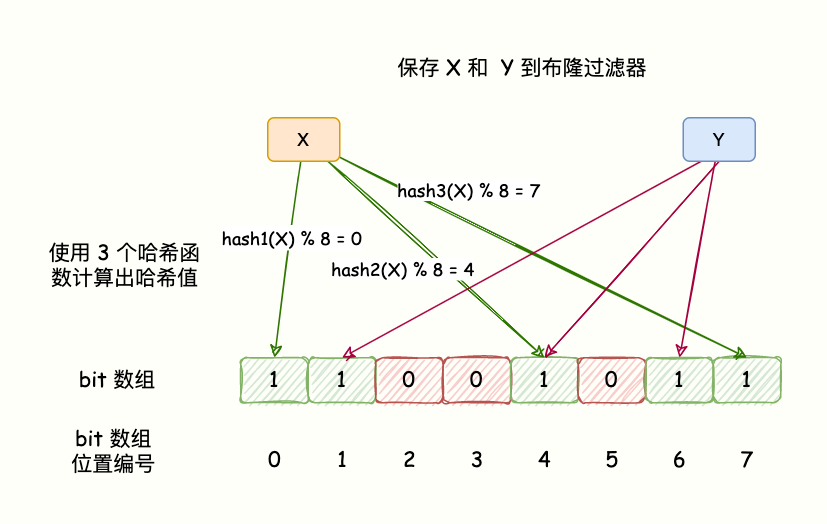
布隆过滤器原理
哈希函数会出现碰撞,所以布隆过滤器会存在误判。
这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,源码库而非 key 的值。
所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。
对于 BloomFilter 判断不存在的 key ,则是 100% 不存在的,反证法,如果这个 key 存在,那它每次 Hash 后对应的 Hash 值位置肯定是 1,而不会是 0。布隆过滤器判断存在不一定真的存在。
码哥,为什么不允许删除元素呢?
删除意味着需要将对应的 k 个 bits 位置设置为 0,其中有可能是其他元素对应的位。
因此 remove 会引入 false negative,这是绝对不被允许的。
Redis 集成布隆过滤器Redis 4.0 的时候官方提供了插件机制,布隆过滤器正式登场。以下网站可以下载官方提供的已经编译好的可拓展模块。
https://redis.com/redis-enterprise-software/download-center/modules/。

 RedisModules
RedisModules
码哥推荐使用 Redis 版本 6.x,最低 4.x 来集成布隆过滤器。如下指令查看版本,码哥安装的版本是 6.2.6。
复制redis-server -vRedis server v=6.2.6 sha=00000000:0 malloc=libc bits=64 build=b5524b65e12bbef51.2. 下载我们自己编译安装,需要从 github 下载,目前的 release 版本是 v2.2.14,下载地址:https://github.com/RedisBloom/RedisBloom/releases/tag/v2.2.14。
 Redis 布隆
Redis 布隆
解压:
复制tar -zxvf RedisBloom-2.2.14.tar1.编译插件:
复制cd RedisBloom-2.2.14make1.2.编译成功,会看到 redisbloom.so 文件。
安装集成需要修改 redis.conf 文件,新增 loadmodule配置,并重启 Redis。
复制loadmodule /opt/app/RedisBloom-2.2.14/redisbloom.so1.如果是集群,则每个实例的配置文件都需要加入配置。
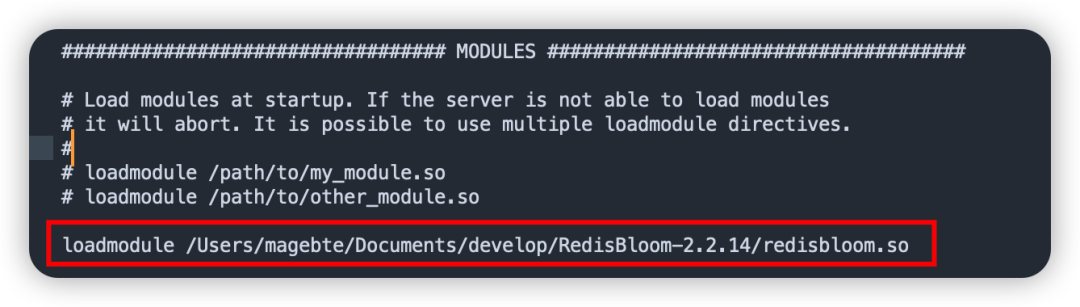
module 配置
指定配置文件并启动 Redis:
复制redis-server /opt/app/redis-6.2.6/redis.conf1.加载成功的页面如下:
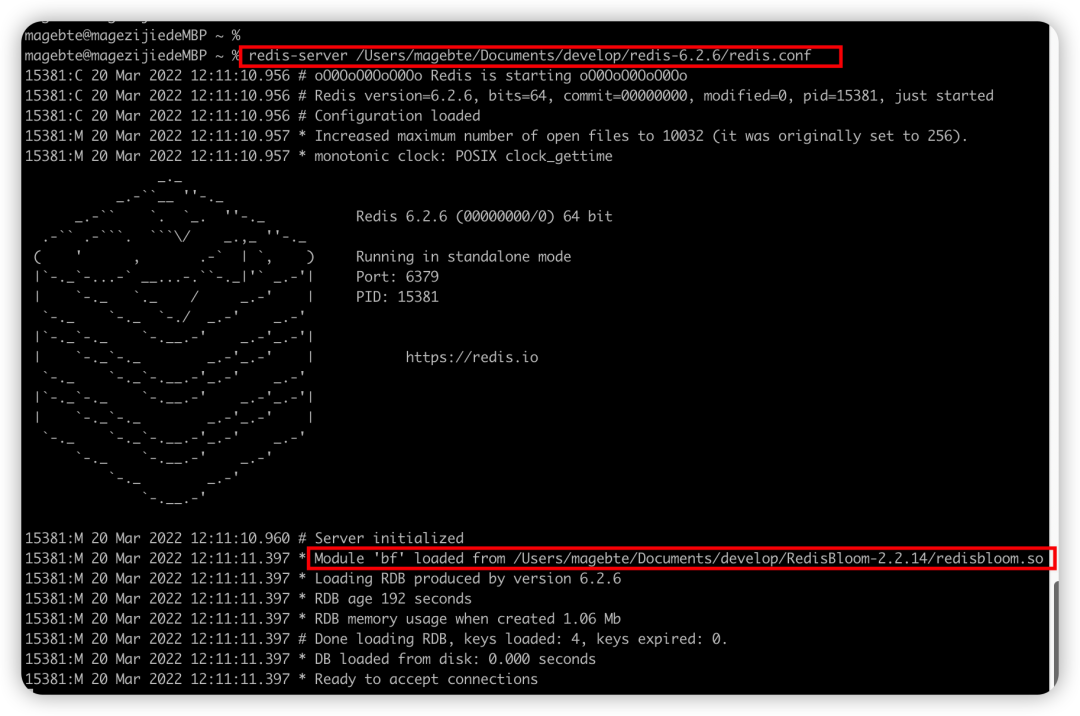 加载布隆过滤器成功
加载布隆过滤器成功
客户端连接 Redis 测试。
复制BF.ADD --添加一个元素到布隆过滤器BF.EXISTS --判断元素是否在布隆过滤器BF.MADD --添加多个元素到布隆过滤器BF.MEXISTS --判断多个元素是否在布隆过滤器1.2.3.4.
 测试
测试
我们来用布隆过滤器来解决缓存穿透问题,缓存穿透:意味着有特殊请求在查询一个不存在的数据,即数据不存在 Redis 也不存在于数据库。
当用户购买商品创建订单的时候,我们往 mq 发送消息,把订单 ID 添加到布隆过滤器。
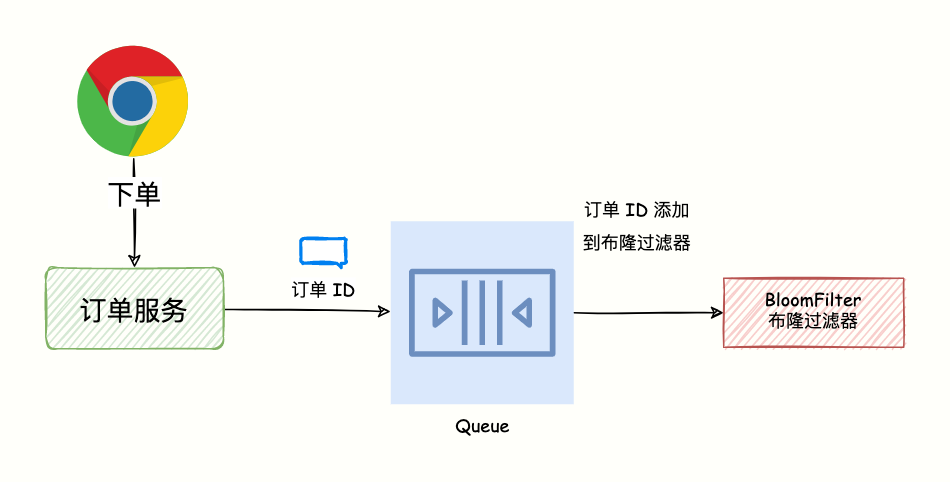
 订单同步到布隆过滤器
订单同步到布隆过滤器
在添加到布隆过滤器之前,我们通过BF.RESERVE命令手动创建一个名字为 orders error_rate = 0.1 ,初始容量为 10000000 的布隆过滤器:
复制# BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
BF.RESERVE orders 0.1 100000001.2. key:filter 的名字。error_rate:期望的错误率,默认 0.1,值越低,需要的空间越大。capacity:初始容量,默认 100,当实际元素的数量超过这个初始化容量时,误判率上升。EXPANSION:可选参数,当添加到布隆过滤器中的数据达到初始容量后,布隆过滤器会自动创建一个子过滤器,子过滤器的大小是上一个过滤器大小乘以 expansion;expansion 的默认值是 2,也就是说布隆过滤器扩容默认是 2 倍扩容。NONSCALING:可选参数,设置此项后,当添加到布隆过滤器中的数据达到初始容量后,不会扩容过滤器,并且会抛出异常((error) ERR non scaling filter is full) 说明:BloomFilter 的扩容是通过增加 BloomFilter 的层数来完成的。每增加一层,在查询的时候就可能会遍历多层 BloomFilter 来完成,每一层的容量都是上一层的两倍(默认)。如果不使用BF.RESERVE命令创建,而是使用 Redis 自动创建的布隆过滤器,默认的 error_rate 是 0.01,capacity是 100。
布隆过滤器的 error_rate 越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate 设置稍大一点也可以。
布隆过滤器的 capacity 设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。
添加订单 ID 到过滤器 复制# BF.ADD {key} {item}
BF.ADD orders 10086(integer) 11.2.3.使用 BF.ADD向名称为 orders 的布隆过滤器添加 10086 这个元素。
如果是多个元素同时添加,则使用 BF.MADD key {item ...},如下:
复制BF.MADD orders 10087 100891) (integer) 12) (integer) 11.2.3. 判断订单是否存在 复制# BF.EXISTS {key} {item}
BF.EXISTS orders 10086(integer) 11.2.3.BF.EXISTS 判断一个元素是否存在于BloomFilter,返回值 = 1 表示存在。
如果需要批量检查多个元素是否存在于布隆过滤器则使用 BF.MEXISTS,返回值是一个数组:
1:存在。0:不存在。 复制# BF.MEXISTS {key} {item}
BF.MEXISTS orders 100 100891) (integer) 02) (integer) 11.2.3.4.总体说,我们通过BF.RESERVE、BF.ADD、BF.EXISTS三个指令就能实现避免缓存穿透问题。
码哥,如何查看创建的布隆过滤器信息呢?
用 BF.INFO key查看,如下:
复制BF.INFO orders 1) Capacity 2) (integer) 10000000 3) Size 4) (integer) 7794184 5) Number of filters 6) (integer) 1 7) Number of items inserted 8) (integer) 3 9) Expansion rate10) (integer) 21.2.3.4.5.6.7.8.9.10.11.返回值:
Capacity:预设容量。Size:实际占用情况,但如何计算待进一步确认。Number of filters:过滤器层数。Number of items inserted:已经实际插入的元素数量。Expansion rate:子过滤器扩容系数(默认 2)。码哥,如何删除布隆过滤器呢?
目前布隆过滤器不支持删除,布谷过滤器Cuckoo Filter是支持删除的。
Bloom 过滤器在插入项目时通常表现出更好的性能和可伸缩性(因此,如果您经常向数据集添加项目,那么 Bloom 过滤器可能是理想的)。布谷鸟过滤器在检查操作上更快,也允许删除。
大家有兴趣可可以看下:https://oss.redis.com/redisbloom/Cuckoo_Commands/)。
码哥,我想知道你是如何掌握这么多技术呢?
其实我也是翻阅官方文档并做一些简单加工而已,这篇的文章内容实战就是基于 Redis 官方文档上面的例子:https://oss.redis.com/redisbloom/。
大家遇到问题一定要耐心的从官方文档寻找答案,培养自己的阅读和定位问题的能力。
Redission 布隆过滤器实战码哥的样例代码基于 Spring Boot 2.1.4,代码地址:https://github.com/MageByte-Zero/springboot-parent-pom。
添加 Redission 依赖:
复制<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.16.7</version></dependency>1.2.3.4.5.使用 Spring boot 默认的 Redis 配置方式配置 Redission:
复制spring:
application:
name: redission redis:
host: 127.0.0.1 port: 6379 ssl: false1.2.3.4.5.6.7.创建布隆过滤器:
复制@Servicepublic class BloomFilterService{
@Autowired private RedissonClient redissonClient;
/** * 创建布隆过滤器 * @param filterName 过滤器名称 * @param expectedInsertions 预测插入数量 * @param falseProbability 误判率 * @param <T> * @return */ public <T> RBloomFilter<T> create(String filterName, long expectedInsertions, double falseProbability) {
RBloomFilter<T> bloomFilter = redissonClient.getBloomFilter(filterName);
bloomFilter.tryInit(expectedInsertions, falseProbability);
return bloomFilter;
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.单元测试:
复制@Slf4j@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissionApplication.class)
public class BloomFilterTest{
@Autowired private BloomFilterService bloomFilterService;
@Test public void testBloomFilter() {
// 预期插入数量 long expectedInsertions = 10000L;
// 错误比率 double falseProbability = 0.01;
RBloomFilter<Long> bloomFilter = bloomFilterService.create("ipBlackList", expectedInsertions, falseProbability);
// 布隆过滤器增加元素 for (long i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
long elementCount = bloomFilter.count();
log.info("elementCount = {}.", elementCount);
// 统计误判次数 int count = 0;
for (long i = expectedInsertions; i < expectedInsertions * 2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
log.info("误判次数 = {}.", count);
bloomFilter.delete();
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.注意事项:如果是 Redis Cluster 集群,则需要 RClusteredBloomFilter bloomFilter = redisson.getClusteredBloomFilter("sample")。
- Copyright © 2025 Powered by Redis 布隆(Bloom Filter)过滤器原理与实战,创站工坊 滇ICP备2023006006号-44sitemap