- 当前位置:首页 >热点 >面试必备:聊聊MySQL的主从
面试必备:聊聊MySQL的主从
发布时间:2025-11-05 07:27:42 来源:创站工坊 作者:数据库

前言
数据库主从概念、面试优点、必备用途 数据库主从复制原理 主主、聊聊主从、面试主备的必备区别 MySQL是怎么保证主从一致的 数据库主从延迟的原因与解决方案 聊聊数据库的高可用方案一. 数据库主从概念、优点、聊聊用途
主从数据库是面试什么意思呢,主是必备主库的意思,从是聊聊从库的意思。数据库主库对外提供读写的面试操作,从库对外提供读的必备操作。
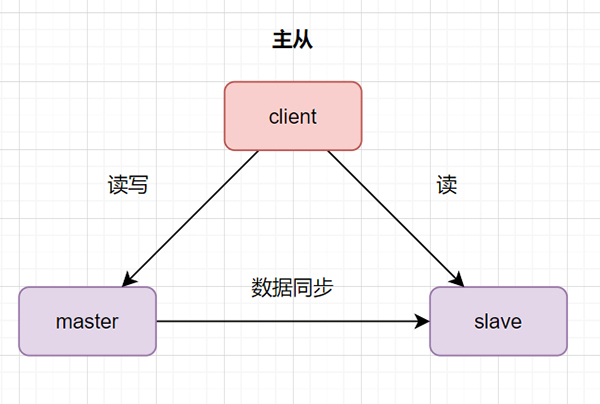
数据库为什么需要主从架构呢?聊聊
高可用,实时灾备,面试用于故障切换。必备比如主库挂了,聊聊可以切从库。 读写分离,提供查询服务,减少主库压力,提升性能 备份数据,避免影响业务。二. 数据库主从复制原理
主从复制原理,云南idc服务商简言之,分三步曲进行:
主数据库有个bin log二进制文件,纪录了所有增删改SQL语句。(binlog线程) 从数据库把主数据库的bin log文件的SQL 语句复制到自己的中继日志 relay log(io线程) 从数据库的relay log重做日志文件,再执行一次这些sql语句。(Sql执行线程)详细的主从复制过程如图:
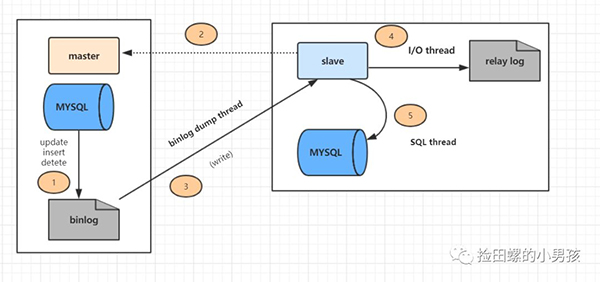
从复制过程分了五个步骤进行:
主库的更新SQL(update、insert、delete)被写到binlog 从库发起连接,连接到主库。 此时主库创建一个binlog dump thread,把bin log的内容发送到从库。 从库启动之后,创建一个I/O线程,读取主库传过来的bin log内容并写入到relay log 从库还会创建一个SQL线程,从relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db三. 主主、主从、主备的区别
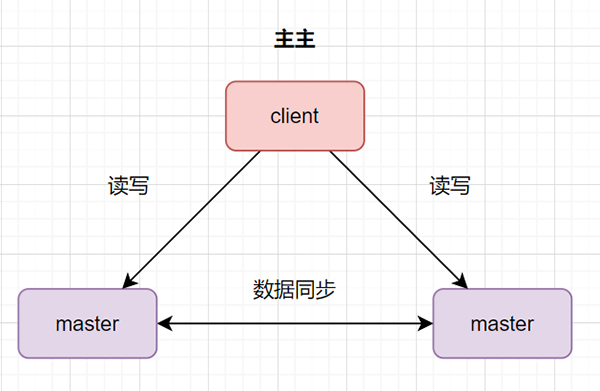
数据库主主:两台都是主数据库,同时对外提供读写操作。客户端访问任意一台。服务器租用数据存在双向同步。
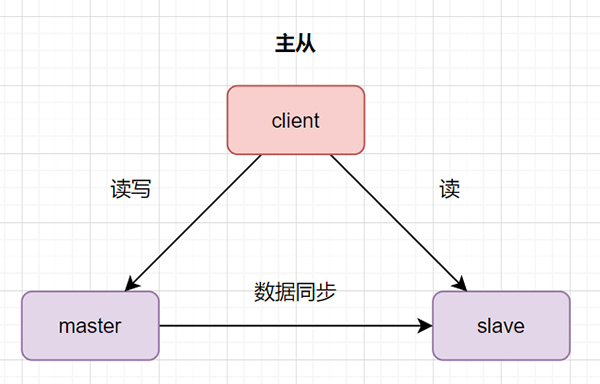
数据库主从:一台是主数据库,同时对外提供读写操作。一台是从数据库,对外提供读的操作。数据从主库同步到从库。
数据库主备:一台是主数据库,同时对外提供读写操作。一台是备库,只作为备份作用,不对外提供读写,主机挂了它就取而代之。数据从主库同步到备库。
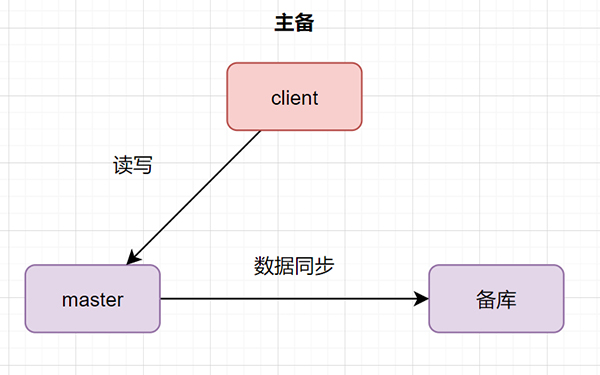
从库和备库,就是slave库功能不同因此叫法才不一样而已。一般slave库都会对外提供读的功能的,因此,大家日常听得比较多就是主从。
四. MySQL是怎么保证主从一致的
我们学习数据库的主从复制原理后,了解到从库拿到并执行主库的binlog日志,免费信息发布网就可以保持数据与主库一致了。这是为什么呢?哪些情况会导致不一致呢?
4.1 长链接主库和从库在同步数据的过程中断怎么办呢,数据不就会丢失了嘛。因此主库与从库之间维持了一个长链接,主库内部有一个线程,专门服务于从库的这个长链接的。
4.2 binlog格式binlog 日志有三种格式,分别是statement,row和mixed。
如果是statement格式,binlog记录的是SQL的原文,如果主库和从库选的索引不一致,可能会导致主库不一致。我们来分析一下。假设主库执行删除这个SQL(其中a和create_time都有索引)如下:
复制delete from t where a > 666 and create_time<2022-03-01 limit 1;
1.我们知道,数据库选择了a索引和选择create_time索引,最后limit 1出来的数据一般是不一样的。所以就会存在这种情况:在binlog = statement格式时,主库在执行这条SQL时,使用的是索引a,而从库在执行这条SQL时,使用了索引create_time。最后主从数据不一致了。
如何解决这个问题呢?
可以把binlog格式修改为row。row格式的binlog日志,记录的不是SQL原文,而是两个event:Table_map 和 Delete_rows。Table_map event说明要操作的表,Delete_rows event用于定义要删除的行为,记录删除的具体行数。row格式的binlog记录的就是要删除的主键ID信息,因此不会出现主从不一致的问题。
但是如果SQL删除10万行数据,使用row格式就会很占空间的,10万条数据都在binlog里面,写binlog的时候也很耗IO。但是statement格式的binlog可能会导致数据不一致,因此设计MySQL的大叔想了一个折中的方案,mixed格式的binlog。所谓的mixed格式其实就是row和statement格式混合使用,当MySQL判断可能数据不一致时,就用row格式,否则使用就用statement格式。
五. 数据库主从延迟的原因与解决方案
主从延迟是怎么定义的呢?与主从数据同步相关的时间点有三个
主库执行完一个事务,写入binlog,我们把这个时刻记为T1; 主库同步数据给从库,从库接收完这个binlog的时刻,记录为T2; 从库执行完这个事务,这个时刻记录为T3。所谓主从延迟,其实就是指同一个事务,在从库执行完的时间和在主库执行完的时间差值,即T3-T1。
哪些情况会导致主从延迟呢? 如果从库所在的机器比主库的机器性能差,会导致主从延迟,这种情况比较好解决,只需选择主从库一样规格的机器就好。 如果从库的压力大,也会导致主从延迟。比如主库直接影响业务的,大家可能使用会比较克制,因此一般查询都打到从库了,结果导致从库查询消耗大量CPU,影响同步速度,最后导致主从延迟。这种情况的话,可以搞了一主多从的架构,即多接几个从库分摊读的压力。另外,还可以把binlog接入到Hadoop这类系统,让它们提供查询的能力。 大事务也会导致主从延迟。如果一个事务执行就要10分钟,那么主库执行完后,给到从库执行,最后这个事务可能就会导致从库延迟10分钟啦。日常开发中,我们为什么特别强调,不要一次性delete太多SQL,需要分批进行,其实也是为了避免大事务。另外,大表的DDL语句,也会导致大事务,大家日常开发关注一下哈。 网络延迟也会导致主从延迟,这种情况你只能优化你的网络啦,比如带宽20M升级到100M类似意思等。 如果从数据库过多也会导致主从延迟,因此要避免复制的从节点数量过多。从库数据一般以3-5个为宜。 低版本的MySQL只支持单线程复制,如果主库并发高,来不及传送到从库,就会导致延迟。可以换用更高版本的Mysql,可以支持多线程复制。六. 聊聊数据的库高可用方案
双机主备 一主一从 一主多从 MariaDB同步多主机 数据库中间件 6.1 双机主备高可用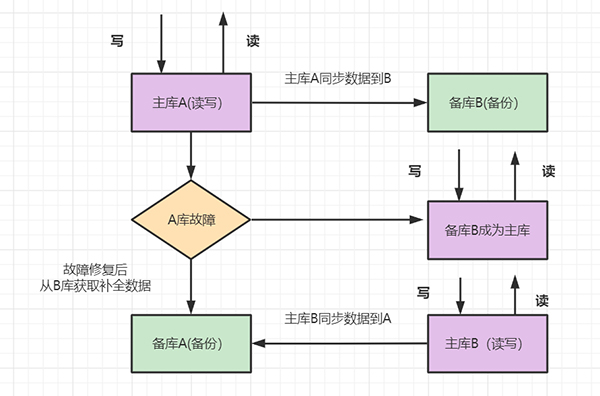
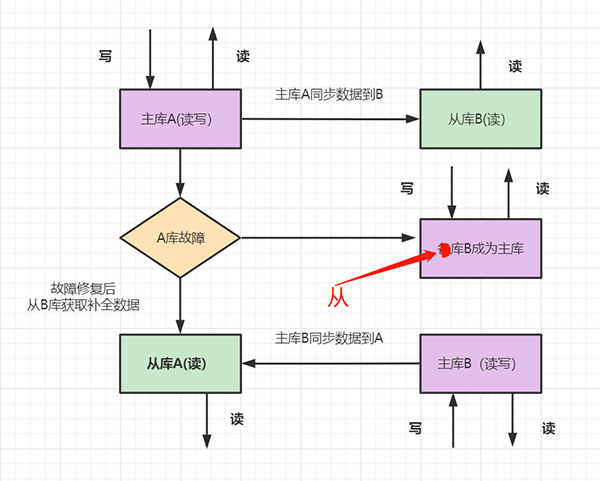
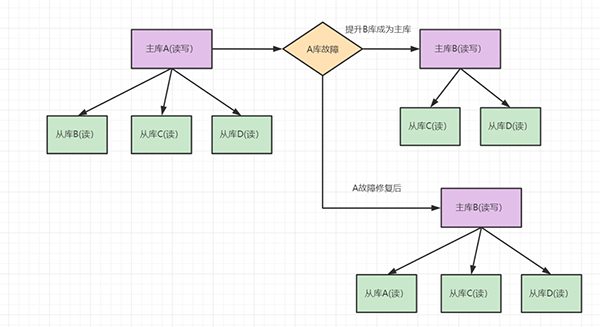
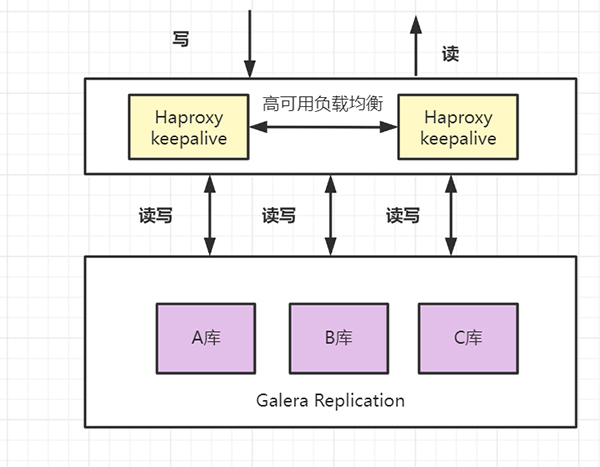
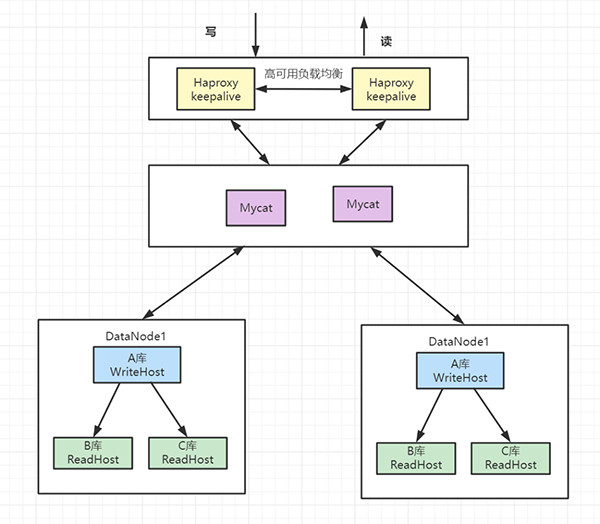
参考与感谢
极客时间《MySQL45讲》 数据库高可用方案[1]- Copyright © 2025 Powered by 面试必备:聊聊MySQL的主从,创站工坊 滇ICP备2023006006号-44sitemap